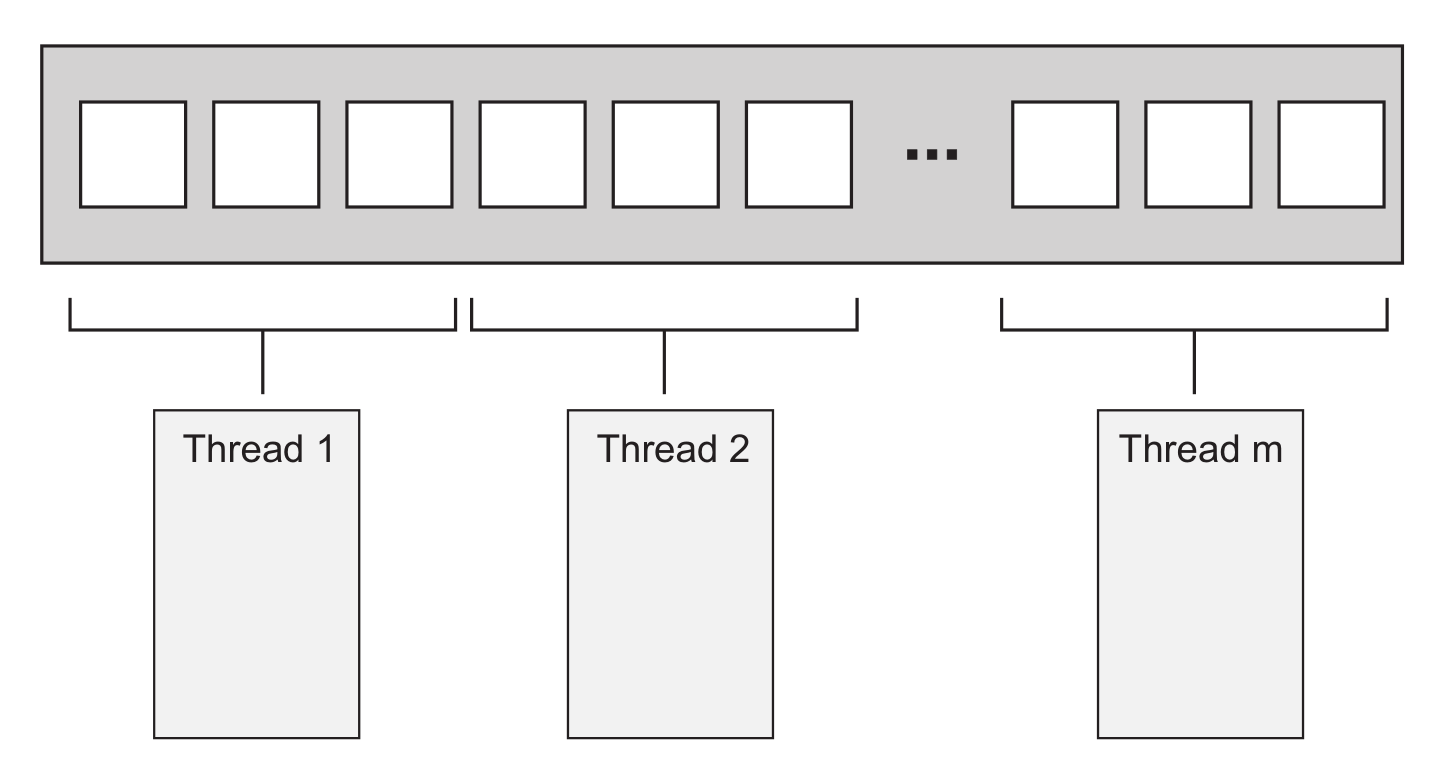
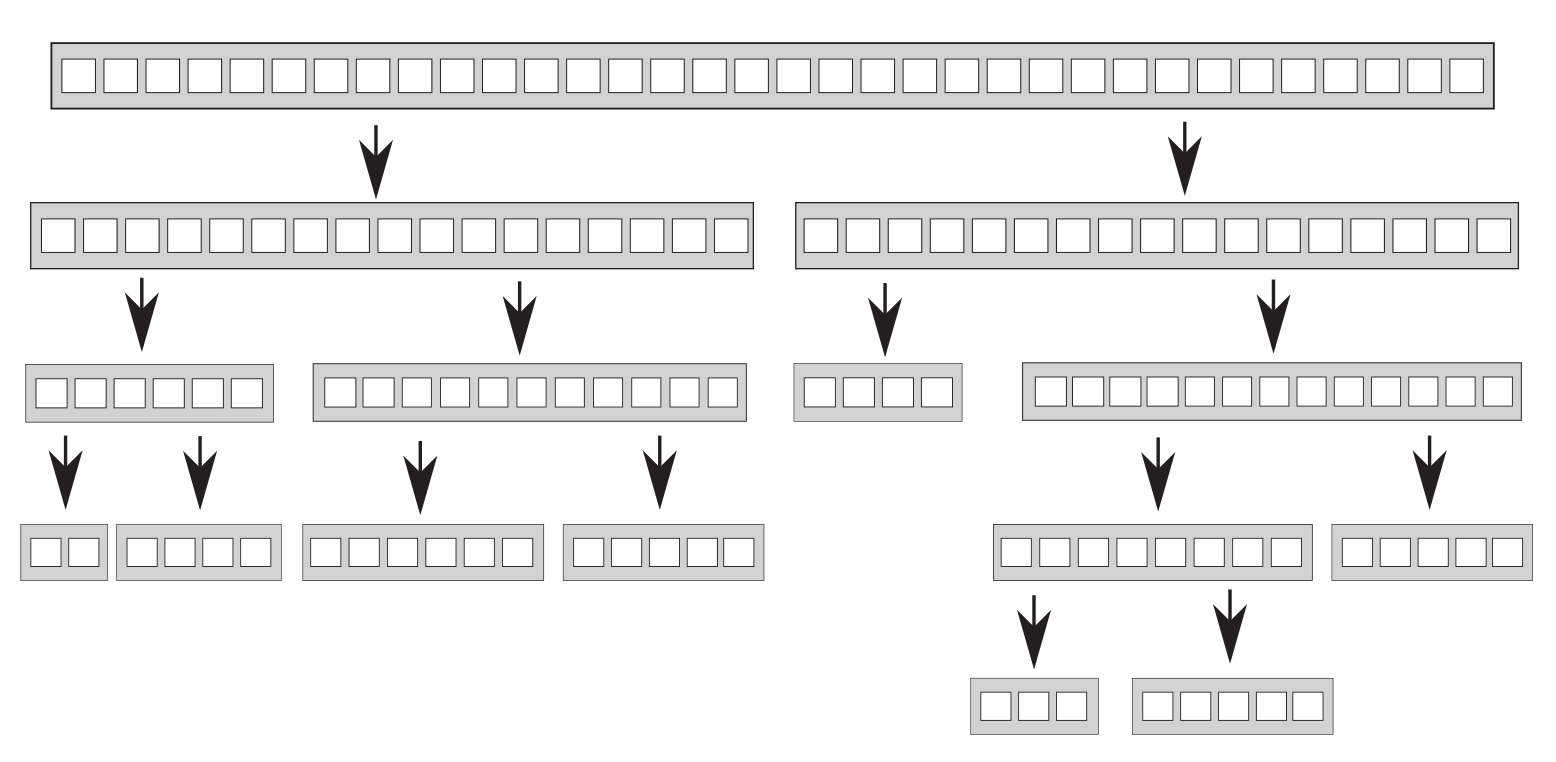
#include <algorithm>
#include <cassert>
#include <future>
#include <list>
template <typename T>
std::list<T> parallel_quick_sort(std::list<T> v) {
if (v.empty()) {
return {};
}
std::list<T> res;
res.splice(res.begin(), v, v.begin());
auto it = std::partition(v.begin(), v.end(),
[&](const T& x) { return x < res.front(); });
std::list<T> low;
low.splice(low.end(), v, v.begin(), it);
std::future<std::list<T>> l(
std::async(¶llel_quick_sort<T>, std::move(low)));
auto r(parallel_quick_sort(std::move(v)));
res.splice(res.end(), r);
res.splice(res.begin(), l.get());
return res;
}
int main() {
std::list<int> input = {5, 1, 9, 2, 9, 100, 8};
std::list<int> expected = {1, 2, 5, 8, 9, 9, 100};
assert(parallel_quick_sort(input) == expected);
}
#include <algorithm>
#include <atomic>
#include <future>
#include <list>
#include <memory>
#include <thread>
#include <vector>
#include "concurrent_stack.hpp"
template <typename T>
class Sorter {
public:
Sorter() : max_thread_count(std::thread::hardware_concurrency() - 1) {}
~Sorter() {
end_of_data = true;
for (auto& x : threads) {
if (x.joinable()) {
x.join();
}
}
}
std::list<T> do_sort(std::list<T>& v) {
if (v.empty()) {
return {};
}
std::list<T> res;
res.splice(res.begin(), v, v.begin());
auto it = std::partition(v.begin(), v.end(),
[&](const T& x) { return x < res.front(); });
ChunkToSort low;
low.data.splice(low.data.end(), v, v.begin(), it);
std::future<std::list<T>> l = low.promise.get_future();
chunks.push(std::move(low));
if (threads.size() < max_thread_count) {
threads.emplace_back(&Sorter<T>::sort_thread, this);
}
auto r{do_sort(v)};
res.splice(res.end(), r);
while (l.wait_for(std::chrono::seconds(0)) != std::future_status::ready) {
try_sort_chunk();
}
res.splice(res.begin(), l.get());
return res;
}
private:
struct ChunkToSort {
std::list<T> data;
std::promise<std::list<T>> promise;
};
private:
void sort_chunk(const std::shared_ptr<ChunkToSort>& chunk) {
chunk->promise.set_value(do_sort(chunk->data));
}
void try_sort_chunk() {
std::shared_ptr<ChunkToSort> chunk = chunks.pop();
if (chunk) {
sort_chunk(chunk);
}
}
void sort_thread() {
while (!end_of_data) {
try_sort_chunk();
std::this_thread::yield();
}
}
private:
ConcurrentStack<ChunkToSort> chunks;
std::vector<std::thread> threads;
const std::size_t max_thread_count;
std::atomic<bool> end_of_data = false;
};
template <typename T>
std::list<T> parallel_quick_sort(std::list<T> v) {
if (v.empty()) {
return {};
}
return Sorter<T>{}.do_sort(v);
}
// 非 pipeline:每 20 秒 4 个数据(每个数据仍要 20 秒)
线程A:-1- -1- -1- -1- -5- -5- -5- -5-
线程B:-2- -2- -2- -2- -6- -6- -6- -6-
线程C:-3- -3- -3- -3- -7- -7- -7- -7-
线程D:-4- -4- -4- -4- -8- -8- -8- -8-
// pipeline:第一个数据 20 秒,之后每个 5 秒
线程A:-1- -2- -3- -4- -5- -6- -7- -8-
线程B:--- -1- -2- -3- -4- -5- -6- -7-
线程C:--- --- -1- -2- -3- -4- -5- -6-
线程D:--- --- --- -1- -2- -3- -4- -5-
#include <algorithm>
#include <functional>
#include <numeric>
#include <thread>
#include <vector>
template <typename Iterator, typename T>
struct accumulate_block {
void operator()(Iterator first, Iterator last, T& res) {
res = std::accumulate(first, last, res); // 可能抛异常
}
};
template <typename Iterator, typename T>
T parallel_accumulate(Iterator first, Iterator last, T init) {
std::size_t len = std::distance(first, last); // 此时没做任何事,抛异常无影响
if (!len) {
return init;
}
std::size_t min_per_thread = 25;
std::size_t max_threads = (len + min_per_thread - 1) / min_per_thread;
std::size_t hardware_threads = std::thread::hardware_concurrency();
std::size_t num_threads =
std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
std::size_t block_size = len / num_threads;
std::vector<T> res(num_threads); // 仍未做任何事,抛异常无影响
std::vector<std::thread> threads(num_threads - 1); // 同上
Iterator block_start = first; // 同上
for (std::size_t i = 0; i < num_threads - 1; ++i) {
Iterator block_end = block_start; // 同上
std::advance(block_end, block_size);
// 下面创建 std::thread,抛异常就导致析构对象,并调用 std::terminate
// 终止程序
threads[i] = std::thread(accumulate_block<Iterator, T>{}, block_start,
block_end, std::ref(res[i]));
block_start = block_end;
}
// accumulate_block::operator() 调用的 std::accumulate
// 可能抛异常,此时抛异常造成问题同上
accumulate_block<Iterator, T>()(block_start, last, res[num_threads - 1]);
std::for_each(threads.begin(), threads.end(),
std::mem_fn(&std::thread::join));
// 最后调用 std::accumulate 可能抛异常,但不引发大问题,因为所有线程已 join
return std::accumulate(res.begin(), res.end(), init);
}
#include <algorithm>
#include <functional>
#include <future>
#include <numeric>
#include <thread>
#include <vector>
template <typename Iterator, typename T>
struct accumulate_block {
T operator()(Iterator first, Iterator last) {
return std::accumulate(first, last, T{});
}
};
template <typename Iterator, typename T>
T parallel_accumulate(Iterator first, Iterator last, T init) {
std::size_t len = std::distance(first, last);
if (!len) {
return init;
}
std::size_t min_per_thread = 25;
std::size_t max_threads = (len + min_per_thread - 1) / min_per_thread;
std::size_t hardware_threads = std::thread::hardware_concurrency();
std::size_t num_threads =
std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
std::size_t block_size = len / num_threads;
std::vector<std::future<T>> fts(num_threads - 1); // 改用 std::future 获取值
std::vector<std::thread> threads(num_threads - 1);
Iterator block_start = first;
for (std::size_t i = 0; i < num_threads - 1; ++i) {
Iterator block_end = block_start;
std::advance(block_end, block_size);
// 用 std::packaged_task 替代直接创建 std::thread
std::packaged_task<T(Iterator, Iterator)> pt(
accumulate_block<Iterator, T>{});
fts[i] = pt.get_future();
threads[i] = std::thread(std::move(pt), block_start, block_end);
block_start = block_end;
}
T last_res = accumulate_block<Iterator, T>{}(block_start, last);
std::for_each(threads.begin(), threads.end(),
std::mem_fn(&std::thread::join));
T res = init;
try {
for (std::size_t i = 0; i < num_threads - 1; ++i) {
res += fts[i].get();
}
res += last_res;
} catch (...) {
for (auto& x : threads) {
if (x.joinable()) {
x.join();
}
}
throw;
}
return res;
}
#include <algorithm>
#include <functional>
#include <future>
#include <numeric>
#include <thread>
#include <vector>
class threads_guard {
public:
explicit threads_guard(std::vector<std::thread>& threads)
: threads_(threads) {}
~threads_guard() {
for (auto& x : threads_) {
if (x.joinable()) {
x.join();
}
}
}
private:
std::vector<std::thread>& threads_;
};
template <typename Iterator, typename T>
struct accumulate_block {
T operator()(Iterator first, Iterator last) {
return std::accumulate(first, last, T{});
}
};
template <typename Iterator, typename T>
T parallel_accumulate(Iterator first, Iterator last, T init) {
std::size_t len = std::distance(first, last);
if (!len) {
return init;
}
std::size_t min_per_thread = 25;
std::size_t max_threads = (len + min_per_thread - 1) / min_per_thread;
std::size_t hardware_threads = std::thread::hardware_concurrency();
std::size_t num_threads =
std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
std::size_t block_size = len / num_threads;
std::vector<std::future<T>> fts(num_threads - 1);
std::vector<std::thread> threads(num_threads - 1);
threads_guard g{threads}; // threads 元素析构时自动 join
Iterator block_start = first;
for (std::size_t i = 0; i < num_threads - 1; ++i) {
Iterator block_end = block_start;
std::advance(block_end, block_size);
std::packaged_task<T(Iterator, Iterator)> pt(
accumulate_block<Iterator, T>{});
fts[i] = pt.get_future();
threads[i] = std::thread(std::move(pt), block_start, block_end);
block_start = block_end;
}
T last_res = accumulate_block<Iterator, T>{}(block_start, last);
std::for_each(threads.begin(), threads.end(),
std::mem_fn(&std::thread::join));
T res = init;
for (std::size_t i = 0; i < num_threads - 1; ++i) {
res += fts[i].get();
}
res += last_res;
return res;
}
#include <algorithm>
#include <functional>
#include <future>
#include <numeric>
#include <thread>
#include <vector>
template <typename Iterator, typename T>
struct accumulate_block {
T operator()(Iterator first, Iterator last) {
return std::accumulate(first, last, T{});
}
};
template <typename Iterator, typename T>
T parallel_accumulate(Iterator first, Iterator last, T init) {
std::size_t len = std::distance(first, last);
if (!len) {
return init;
}
std::size_t min_per_thread = 25;
std::size_t max_threads = (len + min_per_thread - 1) / min_per_thread;
std::size_t hardware_threads = std::thread::hardware_concurrency();
std::size_t num_threads =
std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
std::size_t block_size = len / num_threads;
std::vector<std::future<T>> fts(num_threads - 1);
std::vector<std::jthread> threads(num_threads - 1);
Iterator block_start = first;
for (std::size_t i = 0; i < num_threads - 1; ++i) {
Iterator block_end = block_start;
std::advance(block_end, block_size);
std::packaged_task<T(Iterator, Iterator)> pt(
accumulate_block<Iterator, T>{});
fts[i] = pt.get_future();
threads[i] = std::jthread(std::move(pt), block_start, block_end);
block_start = block_end;
}
T last_res = accumulate_block<Iterator, T>{}(block_start, last);
std::for_each(threads.begin(), threads.end(),
std::mem_fn(&std::jthread::join));
T res = init;
for (std::size_t i = 0; i < num_threads - 1; ++i) {
res += fts[i].get();
}
res += last_res;
return res;
}
#include <future>
#include <numeric>
template <typename Iterator, typename T>
T parallel_accumulate(Iterator first, Iterator last, T init) {
std::size_t len = std::distance(first, last);
std::size_t max_chunk_size = 25;
if (len <= max_chunk_size) {
return std::accumulate(first, last, init);
}
Iterator mid_point = first;
std::advance(mid_point, len / 2);
std::future<T> l =
std::async(parallel_accumulate<Iterator, T>, first, mid_point, init);
// 递归调用如果抛出异常,std::async 创建的 std::future 将在异常传播时被析构
T r = parallel_accumulate(mid_point, last, T{});
// 如果异步任务抛出异常,get 就会捕获异常并重新抛出
return l.get() + r;
}
S = 1 / (a + (1 - a) / N) // a 为串行部分占比,N 为处理器倍数,S 为性能倍数
// 正常情况下 S < 1 /a,最理想的情况是 a 为 0,S = N
#include <algorithm>
#include <future>
#include <thread>
#include <vector>
template <typename Iterator, typename Func>
void parallel_for_each(Iterator first, Iterator last, Func f) {
std::size_t len = std::distance(first, last);
if (!len) {
return;
}
std::size_t min_per_thread = 25;
std::size_t max_threads = (len + min_per_thread - 1) / min_per_thread;
std::size_t hardware_threads = std::thread::hardware_concurrency();
std::size_t num_threads =
std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
std::size_t block_size = len / num_threads;
std::vector<std::future<void>> fts(num_threads - 1);
std::vector<std::jthread> threads(num_threads - 1);
Iterator block_start = first;
for (std::size_t i = 0; i < num_threads - 1; ++i) {
Iterator block_end = block_start;
std::advance(block_end, block_size);
std::packaged_task<void(void)> pt(
[=] { std::for_each(block_start, block_end, f); });
fts[i] = pt.get_future();
threads[i] = std::jthread(std::move(pt));
block_start = block_end;
}
std::for_each(block_start, last, f);
for (std::size_t i = 0; i < num_threads - 1; ++i) {
fts[i].get(); // 只是为了传递异常
}
}
#include <algorithm>
#include <future>
template <typename Iterator, typename Func>
void parallel_for_each(Iterator first, Iterator last, Func f) {
std::size_t len = std::distance(first, last);
if (!len) {
return;
}
std::size_t min_per_thread = 25;
if (len < 2 * min_per_thread) {
std::for_each(first, last, f);
return;
}
const Iterator mid_point = first + len / 2;
std::future<void> l =
std::async(¶llel_for_each<Iterator, Func>, first, mid_point, f);
parallel_for_each(mid_point, last, f);
l.get();
}
#include <algorithm>
#include <atomic>
#include <functional>
#include <future>
#include <numeric>
#include <thread>
#include <vector>
template <typename Iterator, typename T>
Iterator parallel_find(Iterator first, Iterator last, T match) {
struct find_element {
void operator()(Iterator begin, Iterator end, T match,
std::promise<Iterator>* res, std::atomic<bool>* done_flag) {
try {
for (; begin != end && !done_flag->load(); ++begin) {
if (*begin == match) {
res->set_value(begin);
done_flag->store(true);
return;
}
}
} catch (...) {
try {
res->set_exception(std::current_exception());
done_flag->store(true);
} catch (...) {
}
}
}
};
std::size_t len = std::distance(first, last);
if (!len) {
return last;
}
std::size_t min_per_thread = 25;
std::size_t max_threads = (len + min_per_thread - 1) / min_per_thread;
std::size_t hardware_threads = std::thread::hardware_concurrency();
std::size_t num_threads =
std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
std::size_t block_size = len / num_threads;
std::promise<Iterator> res;
std::atomic<bool> done_flag(false);
{
std::vector<std::jthread> threads(num_threads - 1);
Iterator block_start = first;
for (auto& x : threads) {
Iterator block_end = block_start;
std::advance(block_end, block_size);
x = std::jthread(find_element{}, block_start, block_end, match, &res,
&done_flag);
block_start = block_end;
}
find_element{}(block_start, last, match, &res, &done_flag);
}
if (!done_flag.load()) {
return last;
}
return res.get_future().get();
}
#include <atomic>
#include <future>
template <typename Iterator, typename T>
Iterator parallel_find_impl(Iterator first, Iterator last, T match,
std::atomic<bool>& done_flag) {
try {
std::size_t len = std::distance(first, last);
std::size_t min_per_thread = 25;
if (len < (2 * min_per_thread)) {
for (; first != last && !done_flag.load(); ++first) {
if (*first == match) {
done_flag = true;
return first;
}
}
return last;
}
const Iterator mid_point = first + len / 2;
std::future<Iterator> async_res =
std::async(¶llel_find_impl<Iterator, T>, mid_point, last, match,
std::ref(done_flag));
const Iterator direct_res =
parallel_find_impl(first, mid_point, match, done_flag);
return direct_res == mid_point ? async_res.get() : direct_res;
} catch (...) {
done_flag = true;
throw;
}
}
template <typename Iterator, typename T>
Iterator parallel_find(Iterator first, Iterator last, T match) {
std::atomic<bool> done_flag(false);
return parallel_find_impl(first, last, match, done_flag);
}
#include <numeric>
#include <vector>
int main() {
std::vector<int> v{1, 2, 3, 4};
std::partial_sum(
v.begin(), v.end(),
std::ostream_iterator<int>(std::cout << "hi"), // 输出到的迭代器起始位置
std::plus<int>{}); // 使用的二元运算符,不指定则默认累加
} // 输出 hi13610
template <class InputIt, class OutputIt, class BinaryOperation>
OutputIt partial_sum(InputIt first, InputIt last, OutputIt d_first,
BinaryOperation op) {
if (first == last) {
return d_first;
}
typename std::iterator_traits<InputIt>::value_type sum = *first;
*d_first = sum;
while (++first != last) {
sum = op(std::move(sum), *first);
*++d_first = sum;
}
return ++d_first;
}
1 1 1 1 1 1 1 1 1 // 输入 9 个 1
// 划分为三部分
1 1 1
1 1 1
1 1 1
// 得到三个部分的结果
1 2 3
1 2 3
1 2 3
// 将第一部分的尾元素(即 3)加到第二部分
1 2 3
4 5 6
1 2 3
// 再将第二部分的尾元素(即 6)加到第三部分
1 2 3
4 5 6
7 8 9
#include <algorithm>
#include <future>
#include <numeric>
template <typename Iterator>
void parallel_partial_sum(Iterator first, Iterator last) {
using value_type = typename Iterator::value_type;
struct process_chunk {
void operator()(Iterator begin, Iterator last,
std::future<value_type>* previous_end_value,
std::promise<value_type>* end_value) {
try {
Iterator end = last;
++end;
std::partial_sum(begin, end, begin);
if (previous_end_value) { // 不是第一个块
value_type addend = previous_end_value->get();
*last += addend;
if (end_value) {
end_value->set_value(*last);
}
std::for_each(begin, last,
[addend](value_type& item) { item += addend; });
} else if (end_value) {
end_value->set_value(*last); // 是第一个块则可以为下个块更新尾元素
}
} catch (...) {
// 如果抛出异常则存储到
// std::promise,异常会传播给下一个块(获取这个块的尾元素时)
if (end_value) {
end_value->set_exception(std::current_exception());
} else {
throw; // 异常最终传给最后一个块,此时再抛出异常
}
}
}
};
std::size_t len = std::distance(first, last);
if (!len) {
return;
}
std::size_t min_per_thread = 25;
std::size_t max_threads = (len + min_per_thread - 1) / min_per_thread;
std::size_t hardware_threads = std::thread::hardware_concurrency();
std::size_t num_threads =
std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
std::size_t block_size = len / num_threads;
// end_values 存储块内尾元素值
std::vector<std::promise<value_type>> end_values(num_threads - 1);
// prev_end_values 检索前一个块的尾元素
std::vector<std::future<value_type>> prev_end_values;
prev_end_values.reserve(num_threads - 1);
Iterator block_start = first;
std::vector<std::jthread> threads(num_threads - 1);
for (std::size_t i = 0; i < num_threads - 1; ++i) {
Iterator block_last = block_start;
std::advance(block_last, block_size - 1); // 指向尾元素
threads[i] = std::jthread(process_chunk{}, block_start, block_last,
i != 0 ? &prev_end_values[i - 1] : nullptr,
&end_values[i]);
block_start = block_last;
++block_start;
prev_end_values.emplace_back(end_values[i].get_future());
}
Iterator final_element = block_start;
std::advance(final_element, std::distance(block_start, last) - 1);
process_chunk{}(block_start, final_element,
num_threads > 1 ? &prev_end_values.back() : nullptr, nullptr);
}
1 1 1 1 1 1 1 1 1 // 输入 9 个 1
// 先让距离为 1 的元素相加
1 2 2 2 2 2 2 2 2
// 再让距离为 2 的元素相加
1 2 3 4 4 4 4 4 4
// 再让距离为 4 的元素相加
1 2 3 4 5 6 7 8 8
// 再让距离为 8 的元素相加
1 2 3 4 5 6 7 8 9